榨干所有性能!9个技巧让你的PyTorch模型训练变得飞快!
不要让你的神经网络变成这样
让我们面对现实吧,你的模型可能还停留在石器时代。我敢打赌你仍然使用32位精度或GASP甚至只在一个GPU上训练。
我明白,网上都是各种神经网络加速指南,但是一个checklist都没有(现在有了),使用这个清单,一步一步确保你能榨干你模型的所有性能。
本指南从最简单的结构到最复杂的改动都有,可以使你的网络得到最大的好处。我会给你展示示例Pytorch代码以及可以在Pytorch- lightning Trainer中使用的相关flags,这样你可以不用自己编写这些代码!
**这本指南是为谁准备的?**任何使用Pytorch进行深度学习模型研究的人,如研究人员、博士生、学者等,我们在这里谈论的模型可能需要你花费几天的训练,甚至是几周或几个月。
我们会讲到:
使用DataLoaders DataLoader中的workers数量 Batch size 梯度累计 保留的计算图 移动到单个 16-bit 混合精度训练 移动到多个GPUs中(模型复制) 移动到多个GPU-nodes中 (8+GPUs) 思考模型加速的技巧
Pytorch-Lightning
你可以在Pytorch的库Pytorch- lightning中找到我在这里讨论的每一个优化。Lightning是在Pytorch之上的一个封装,它可以自动训练,同时让研究人员完全控制关键的模型组件。Lightning 使用最新的最佳实践,并将你可能出错的地方最小化。
我们为MNIST定义LightningModel并使用Trainer来训练模型。
frompytorch_lightningimportTrainermodel=LightningModule(…)trainer=Trainer()trainer.fit(model)
1. DataLoaders
这可能是最容易获得速度增益的地方。保存h5py或numpy文件以加速数据加载的时代已经一去不复返了,使用Pytorch dataloader加载图像数据很简单(对于NLP数据,请查看TorchText)。
在lightning中,你不需要指定训练循环,只需要定义dataLoaders和Trainer就会在需要的时候调用它们。
dataset=MNIST(root=self.hparams.data_root,traintrain=train,download=True)loader=DataLoader(dataset,batch_size=32,shuffle=True)forbatchinloader:x,y=batchmodel.training_step(x,y)...
2. DataLoaders 中的 workers 的数量
另一个加速的神奇之处是允许批量并行加载。因此,您可以一次装载nb_workers个batch,而不是一次装载一个batch。
#slowloader=DataLoader(dataset,batch_size=32,shuffle=True)#fast(use10workers)loader=DataLoader(dataset,batch_size=32,shuffle=True,num_workers=10)
3. Batch size
在开始下一个优化步骤之前,将batch size增大到CPU-RAM或GPU-RAM所允许的最大范围。
下一节将重点介绍如何帮助减少内存占用,以便你可以继续增加batch size。
记住,你可能需要再次更新你的学习率。一个好的经验法则是,如果batch size加倍,那么学习率就加倍。
4. 梯度累加
在你已经达到计算资源上限的情况下,你的batch size仍然太小(比如8),然后我们需要模拟一个更大的batch size来进行梯度下降,以提供一个良好的估计。
假设我们想要达到128的batch size大小。我们需要以batch size为8执行16个前向传播和向后传播,然后再执行一次优化步骤。
#clearlaststepoptimizer.zero_grad()#16accumulatedgradientstepsscaled_loss=0foraccumulated_step_iinrange(16):out=model.forward()loss=some_loss(out,y)loss.backward()scaled_loss+=loss.item()#updateweightsafter8steps.effectivebatch=8*16optimizer.step()#lossisnowscaledupbythenumberofaccumulatedbatchesactual_loss=scaled_loss/16
在lightning中,全部都给你做好了,只需要设置accumulate_grad_batches=16:
trainer=Trainer(accumulate_grad_batches=16)trainer.fit(model)
5. 保留的计算图
一个最简单撑爆你的内存的方法是为了记录日志存储你的loss。
losses=[]...losses.append(loss)print(f'currentloss:{torch.mean(losses)'})
上面的问题是,loss仍然包含有整个图的副本。在这种情况下,调用.item()来释放它。
#badlosses.append(loss)#goodlosses.append(loss.item())
Lightning会非常小心,确保不会保留计算图的副本。
6. 单个GPU训练
一旦你已经完成了前面的步骤,是时候进入GPU训练了。在GPU上的训练将使多个GPU cores之间的数学计算并行化。你得到的加速取决于你所使用的GPU类型。我推荐个人用2080Ti,公司用V100。
乍一看,这可能会让你不知所措,但你真的只需要做两件事:1)移动你的模型到GPU, 2)每当你运行数据通过它,把数据放到GPU上。
#putmodelonGPUmodel.cuda(0)#putdataongpu(cudaonavariablereturnsacudacopy)xx=x.cuda(0)#runsonGPUnowmodel(x)
如果你使用Lightning,你什么都不用做,只需要设置Trainer(gpus=1)。
#asklightningtousegpu0fortrainingtrainer=Trainer(gpus=[0])trainer.fit(model)
在GPU上进行训练时,要注意的主要事情是限制CPU和GPU之间的传输次数。
#expensivexx=x.cuda(0)#veryexpensivexx=x.cpu()xx=x.cuda(0)
如果内存耗尽,不要将数据移回CPU以节省内存。在求助于GPU之前,尝试以其他方式优化你的代码或GPU之间的内存分布。
另一件需要注意的事情是调用强制GPU同步的操作。清除内存缓存就是一个例子。
#reallybadidea.StopsalltheGPUsuntiltheyallcatchuptorch.cuda.empty_cache()
但是,如果使用Lightning,惟一可能出现问题的地方是在定义Lightning Module时。Lightning会特别注意不去犯这类错误。
7. 16-bit 精度
16bit精度是将内存占用减半的惊人技术。大多数模型使用32bit精度数字进行训练。然而,最近的研究发现,16bit模型也可以工作得很好。混合精度意味着对某些内容使用16bit,但将权重等内容保持在32bit。
要在Pytorch中使用16bit精度,请安装NVIDIA的apex库,并对你的模型进行这些更改。
#enable16-bitonthemodelandtheoptimizermodel,optimizers=amp.initialize(model,optimizers,opt_level='O2')#whendoing.backward,letampdoitsoitcanscalethelosswithamp.scale_loss(loss,optimizer)asscaled_loss:scaled_loss.backward()
amp包会处理好大部分事情。如果梯度爆炸或趋向于0,它甚至会缩放loss。
在lightning中,启用16bit并不需要修改模型中的任何内容,也不需要执行我上面所写的操作。设置Trainer(precision=16)就可以了。
trainer=Trainer(amp_level='O2',use_amp=False)trainer.fit(model)
8. 移动到多个GPUs中
现在,事情变得非常有趣了。有3种(也许更多?)方法来进行多GPU训练。
分batch训练
A) 拷贝模型到每个GPU中,B) 给每个GPU一部分batch
第一种方法被称为“分batch训练”。该策略将模型复制到每个GPU上,每个GPU获得batch的一部分。
#copymodeloneachGPUandgiveafourthofthebatchtoeachmodel=DataParallel(model,devices=[0,1,2,3])#outhas4outputs(oneforeachgpu)out=model(x.cuda(0))
在lightning中,你只需要增加GPUs的数量,然后告诉trainer,其他什么都不用做。
#asklightningtouse4GPUsfortrainingtrainer=Trainer(gpus=[0,1,2,3])trainer.fit(model)
模型分布训练
将模型的不同部分放在不同的GPU上,batch按顺序移动
有时你的模型可能太大不能完全放到内存中。例如,带有编码器和解码器的序列到序列模型在生成输出时可能会占用20GB RAM。在本例中,我们希望将编码器和解码器放在独立的GPU上。
#eachmodelissooobigwecan'tfitbothinmemoryencoder_rnn.cuda(0)decoder_rnn.cuda(1)#runinputthroughencoderonGPU0encoder_out=encoder_rnn(x.cuda(0))#runoutputthroughdecoderonthenextGPUout=decoder_rnn(encoder_out.cuda(1))#normallywewanttobringalloutputsbacktoGPU0outout=out.cuda(0)
对于这种类型的训练,在Lightning中不需要指定任何GPU,你应该把LightningModule中的模块放到正确的GPU上。
classMyModule(LightningModule):def__init__():self.encoder=RNN(...)self.decoder=RNN(...)defforward(x):#modelswon'tbemovedafterthefirstforwardbecause#theyarealreadyonthecorrectGPUsself.encoder.cuda(0)self.decoder.cuda(1)out=self.encoder(x)out=self.decoder(out.cuda(1))#don'tpassGPUstotrainermodel=MyModule()trainer=Trainer()trainer.fit(model)
两者混合
在上面的情况下,编码器和解码器仍然可以从并行化操作中获益。
#changetheselinesself.encoder=RNN(...)self.decoder=RNN(...)#tothese#noweachRNNisbasedonadifferentgpusetself.encoder=DataParallel(self.encoder,devices=[0,1,2,3])self.decoder=DataParallel(self.encoder,devices=[4,5,6,7])#inforward...out=self.encoder(x.cuda(0))#noticeinputsonfirstgpuindevicesout=self.decoder(out.cuda(4))#使用多个GPU时要考虑的注意事项:如果模型已经在GPU上了,model.cuda()不会做任何事情。 总是把输入放在设备列表中的第一个设备上。 在设备之间传输数据是昂贵的,把它作为最后的手段。 优化器和梯度会被保存在GPU 0上,因此,GPU 0上使用的内存可能会比其他GPU大得多
9. 多节点GPU训练
每台机器上的每个GPU都有一个模型的副本。每台机器获得数据的一部分,并且只在那部分上训练。每台机器都能同步梯度。
如果你已经做到了这一步,那么你现在可以在几分钟内训练Imagenet了!这并没有你想象的那么难,但是它可能需要你对计算集群的更多知识。这些说明假设你正在集群上使用SLURM。
Pytorch允许多节点训练,通过在每个节点上复制每个GPU上的模型并同步梯度。所以,每个模型都是在每个GPU上独立初始化的,本质上独立地在数据的一个分区上训练,除了它们都从所有模型接收梯度更新。
在高层次上:
在每个GPU上初始化一个模型的副本(确保设置种子,让每个模型初始化到相同的权重,否则它会失败)。 将数据集分割成子集(使用DistributedSampler)。每个GPU只在它自己的小子集上训练。 在.backward()上,所有副本都接收到所有模型的梯度副本。这是模型之间唯一一次的通信。
Pytorch有一个很好的抽象,叫做DistributedDataParallel,它可以帮你实现这个功能。要使用DDP,你需要做4的事情:
deftng_dataloader():d=MNIST()#4:Adddistributedsampler#samplersendsaportionoftngdatatoeachmachinedist_sampler=DistributedSampler(dataset)dataloader=DataLoader(d,shuffle=False,sampler=dist_sampler)defmain_process_entrypoint(gpu_nb):#2:setupconnectionsbetweenallgpusacrossallmachines#allgpusconnecttoasingleGPU"root"#thedefaultusesenv://world=nb_gpus*nb_nodesdist.init_process_group("nccl",rank=gpu_nb,worldworld_size=world)#3:wrapmodelinDPPtorch.cuda.set_device(gpu_nb)model.cuda(gpu_nb)model=DistributedDataParallel(model,device_ids=[gpu_nb])#trainyourmodelnow...if__name__=='__main__':#1:spawnnumberofprocesses#yourclusterwillcallmainforeachmachinemp.spawn(main_process_entrypoint,nprocs=8)
然而,在Lightning中,只需设置节点数量,它就会为你处理其余的事情。
#trainon1024gpusacross128nodestrainer=Trainer(nb_gpu_nodes=128,gpus=[0,1,2,3,4,5,6,7])
Lightning还附带了一个SlurmCluster管理器,可以方便地帮助你提交SLURM作业的正确详细信息。
10. 福利!在单个节点上多GPU更快的训练
事实证明,distributedDataParallel比DataParallel快得多,因为它只执行梯度同步的通信。所以,一个好的hack是使用distributedDataParallel替换DataParallel,即使是在单机上进行训练。
在Lightning中,这很容易通过将distributed_backend设置为ddp和设置GPUs的数量来实现。
#trainon4gpusonthesamemachineMUCHfasterthanDataParalleltrainer=Trainer(distributed_backend='ddp',gpus=[0,1,2,3])
对模型加速的思考
尽管本指南将为你提供了一系列提高网络速度的技巧,但我还是要给你解释一下如何通过查找瓶颈来思考问题。
我将模型分成几个部分:
首先,我要确保在数据加载中没有瓶颈。为此,我使用了我所描述的现有数据加载解决方案,但是如果没有一种解决方案满足你的需要,请考虑离线处理和缓存到高性能数据存储中,比如h5py。
接下来看看你在训练步骤中要做什么。确保你的前向传播速度快,避免过多的计算以及最小化CPU和GPU之间的数据传输。最后,避免做一些会降低GPU速度的事情(本指南中有介绍)。
接下来,我试图最大化我的batch size,这通常是受GPU内存大小的限制。现在,需要关注在使用大的batch size的时候如何在多个GPUs上分布并最小化延迟(比如,我可能会尝试着在多个gpu上使用8000 +的有效batch size)。
然而,你需要小心大的batch size。针对你的具体问题,请查阅相关文献,看看人们都忽略了什么!
标签: PyTorch模型训练 技巧
曝真我GT2 Pro春节前上市 20日举行预沟通会
2022-01-13 06:31:06
一台干衣机每年可向外部环境排出多达1.2亿个微纤维
2022-01-12 23:45:57
罗技发布照明配件Litra Glow 为视频通话与内容创作中的人物补光
2022-01-12 23:45:51
金域医学:主动传播病毒等传言不实 请公众勿造谣传谣
2022-01-12 23:45:44
瑞银CEO:比特币价格今年或达7.5万美元 推动者正是大伙
2022-01-12 23:45:39
iPhone 14 Pro再次被传将配备4800万像素摄像头
2022-01-12 23:45:31
奥斯汀街头骗子盯上停车咪表:放置自制二维码以窃取付款信息
2022-01-12 23:45:23
英国监管机构正式对微软收购Nuance一案展开调查
2022-01-12 23:45:16
Red Hat/Fedora Anaconda迁移到基于网络的新UI
2022-01-12 23:02:56
年轻人的第一台布加迪!布加迪纯电动踏板车发布
2022-01-12 23:02:47
黑客组织Patchwork感染自己开发的恶意程序
2022-01-12 23:02:33
哈勃科技投资物联网的操作系统服务商开鸿
2022-01-12 23:02:26
罗技推出Signature M650鼠标 3款型号 售价249元
2022-01-12 23:02:17
微软发布补丁 修复HTTP协议栈远程执行代码漏洞
2022-01-12 23:02:08
发现最偏心系外行星,每隔几周就会变得非常热
2022-01-12 23:01:56
企查查数据:2021年我国商业航天融资超64.5亿元
2022-01-12 23:01:48
LG加入IBM Quantum Network 推进量子计算的应用
2022-01-12 23:01:41
Windows 11获累积更新 升至Build 22000.434
2022-01-12 23:01:33
T-Mobile声称未大规模屏蔽iCloud隐私中继功能
2022-01-12 23:01:25
Android端Firefox Focus新增隐私保护功能
2022-01-12 23:01:19
大量Wordle“克隆”应用从苹果App Store中消失
2022-01-12 23:01:08
Verizon、AT&T表示未阻止iCloud隐私中继功能
2022-01-12 23:00:57
微软前高管建议剥离Office和Windows 专攻云计算
2022-01-12 23:00:49
指纹解锁共享单车!美团公开新专利
2022-01-12 22:53:06
限制挖矿算力!微星发布三款RTX 3080 12G系列显卡
2022-01-12 22:52:11
三星重振中国市场再出大动作!和京东签署国内战略协议
2022-01-12 22:51:26
还是张朝阳会玩!集结明星在长白山直播三天三夜!
2022-01-12 22:50:17
小米 10S正式推送MIUI 13:桌面更加流畅
2022-01-12 22:48:36
曝真我GT2 Pro春节前上市 20日举行预沟通会
2022-01-12 22:00:38
19岁少年远程入侵25辆特斯拉汽车 称利用软件漏洞
2022-01-12 21:19:34
赴港上市前夜 美菜网被爆总部搬迁、裁员40%
2022-01-12 21:19:27
索尼推出《蜘蛛侠:英雄无归》联名款全新WALKMAN
2022-01-12 21:19:17
魅族冬季新品发布会:lipro、PANDAER、mblu 齐登场
2022-01-12 21:19:00
美国新冠住院人数突破去年峰值 福奇:奥密克戎会传到每一个美国人
2022-01-12 21:18:50
“最冷春节”即将上线 新能源车主开不回老家?
2022-01-12 21:18:42
GeForce RTX 3080 12GB上线电商平台 售价约为1万元
2022-01-12 21:18:34
韩国批准诺瓦瓦克斯新冠疫苗 辉瑞新冠口服药明日送达
2022-01-12 21:18:27
空客2021年共交付611架民用飞机
2022-01-12 21:18:19
Windows Subsystem for Android更新 开始支持GPU切换
2022-01-12 21:18:11
“假笑男孩”祝福视频450元一条:每月在中国都接到订单 量不是特别大
2022-01-12 21:18:02
微商噩梦:微信朋友圈折叠图片新功能悄然上线
2022-01-12 21:17:46
Moto G Stylus 2022最新渲染图揭示其完整外貌:三颗摄像头+打孔屏
2022-01-12 21:17:40
UNITEX推出支持USB连接的LTO-9磁带驱动器
2022-01-12 21:17:31
支持LTE Advanced的Surface Pro 8现在可以从微软官网订购
2022-01-12 18:13:39
Check Point安全报告显示去年企业受到的总体网络攻击量有明显增加
2022-01-12 18:13:33
LG新能源称凭借积压订单将很快击败宁德时代
2022-01-12 18:13:24
Intel NUC迷你机产品线调整 12代酷睿平民版被砍
2022-01-12 18:13:18
美国因感染新冠病毒住院治疗人数达到历史最高水平
2022-01-12 18:13:13
NVIDIA宣布DLDSR AI超分辨率技术:驱动集成、无需游戏优化
2022-01-12 18:13:08
5部手机同时抽中2300元“优惠券” 扫地机器人大奖背后是何套路?
2022-01-12 18:13:02
波音2021年飞机交付量大增 但仍落后于对手空客
2022-01-12 18:12:55
辉瑞疫苗合作商BioNTech:今年新冠疫苗的收入可能会减少
2022-01-12 18:12:50
加拿大研究显示因感染新冠病毒住院的儿童出现严重并发症的风险较高
2022-01-12 18:12:43
加拿大魁北克省将对拒绝接种新冠疫苗者处以高额罚款
2022-01-12 18:12:36

从27个行业标杆,看2022营销与经营风向标|巨量引擎引擎奖榜单公布 (FOR seo)
2022-01-12 16:50:28 
入场2022,从看懂这16个案例开始|巨量引擎引擎奖榜单公布
2022-01-12 14:16:53 iPhone14或采用药丸形打孔屏 最全外形渲染图都在这里了
2022-01-12 13:58:39
LG发布4K 160Hz游戏显示器32GQ950
2022-01-12 13:58:33
iPhone 13 Pro DxO续航测试59小时
2022-01-12 13:58:22
联想拯救者Y90已入网:68W祖传快充
2022-01-12 13:58:16
腾讯全新游戏品牌“腾讯先锋”公布:不用下载
2022-01-12 13:58:08
苹果抛光布重新上架 145元当天发货
2022-01-12 13:46:53
10秒销售额破亿!iQOO 9今日开售战报发布
2022-01-12 13:46:48
文战元宇宙
2022-01-12 13:46:44
下月见!Redmi K50电竞版跑分曝光
2022-01-12 13:46:39
小米有责任,捐赠1000万成立体育奖学金
2022-01-12 13:46:34
配备单色OLED屏 山灵正式发布UA系列便携解码耳放UA5
2022-01-12 13:46:29
荣耀50系列荣获“2021年度经典焕新品牌”
2022-01-12 13:46:23
机构发布报告称智能手表的销量将继续强劲增长
2022-01-12 13:46:17
可选RTX 3070 Ti 150W满功耗释放 联想拯救者 Y9000P 2022将发布
2022-01-12 13:46:12
曝真我GT2 Pro春节前上市 20日举行预沟通会
2022-01-12 13:34:39

2022环境检测机构使命再升级
2022-01-12 09:59:21 
苹果搜歌神器Shazam推出可识别播放歌曲的Chrome浏览器扩展
2022-01-12 08:30:09 
微软突然公开macOS漏洞细节!苹果发文感谢并称已确认修复
2022-01-12 08:28:09 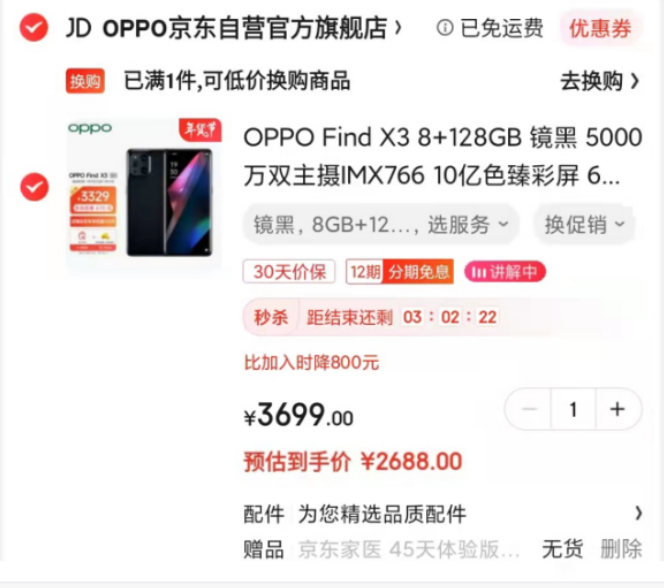
ColorOS 12.1南德TUV A级认证出炉:可坚持36个月流畅不卡顿
2022-01-12 08:26:11 
企业微信4.0正式发布:强化品牌直播带货并全面接入腾讯文档
2022-01-12 08:24:25 
微软为Win11版Defender设计全新界面:调整UI并重构底层界面
2022-01-12 08:22:56 
曝iPhone 14三种屏幕对比图出炉:药丸打孔屏大幅增加屏占比
2022-01-12 08:21:28 
iPhone14或采用药丸形打孔屏:屏占比大幅提升,最高容量2TB
2022-01-12 08:19:22 
曝三星Galaxy S22系列处理器标配高通骁龙8!频率可达1300MHZ
2022-01-12 08:15:03 
NVIDIA宣布DLDSR AI超分辨率技术:可提升任意游戏性能70%
2022-01-12 08:13:37 
PCIe 6.0正式发布:允许数据双向流动,x16带宽增至256GB/s
2022-01-12 08:12:23 苹果:App开发者已经挣了2600亿
2022-01-12 06:16:47
米哈游侧目!腾讯人气手游一年吸金178亿:你贡献多少
2022-01-12 06:16:42
别老拿爱优腾跟Netflix比 根本不是一码事
2022-01-12 06:16:36
Windows 11效率将更高 提高文件管理器性能
2022-01-12 06:16:28
你用多沉的哑铃?这个智能产品对着说就行
2022-01-12 06:16:21
Intel人事调整:CFO退休 新女将接任PC业务主管
2022-01-12 06:16:06
最佳开发商 Xbox可以FaceTime 通话
2022-01-12 06:15:59
全球销量破亿!任天堂Switch OLED国行版开卖 只要2599元
2022-01-12 06:15:55
曝真我GT2 Pro春节前上市 20日举行预沟通会
2022-01-12 06:05:06
从核酸检测到健康码,为什么系统总是“崩了”?
2022-01-12 00:09:00
美联社宣布进军NFT 主打新闻摄影市场
2022-01-12 00:08:55
种植牙将纳入两级医保集采 降价幅度有望达到60%-90%
2022-01-12 00:08:46
1月28日至3月13日,北京禁飞“低慢小”航空器
2022-01-12 00:08:39
邢台18岁女孩百草枯中毒 肺移植后已经可以下床活动
2022-01-12 00:08:33
全球上层海洋温度连续第六年打破纪录
2022-01-12 00:08:28
女外卖骑手的飞驰人生:成为零差评收割机 在男人堆里杀出一条活路
2022-01-12 00:08:17
iPhone 14 Pro与iPhone 13 Pro同框照曝光:新老外形对比强烈
2022-01-12 00:08:10
Rivian在2021年生产了超1000辆电动汽车 符合下调预期
2022-01-11 23:39:04


 营业执照公示信息
营业执照公示信息
相关新闻